Как конфигурировать Alertmanager в Prometheus?
Это статья о конфигурировании Alertmanager для новичков, написана для того, чтобы понять, с чего можно начать. Мы будем использовать пакет prometheus-operator, в поставке которого есть Prometheus и Alertmanager , расположенный по этой ссылке: https://github.com/helm/charts/tree/master/stable/prometheus-operator
Кто есть кто
- Создает уведомления Prometheus! Вы можете найти правила, по которым prometheus генерирует алерты в этой директории:
./templates/prometheus/rules/
Так же вы можете найти их в веб интерфейсе prometheus (страница /alert ).
- Alertmanager только сортирует, группирует, заглушает (часть уведомлений по вашим правилам) , отсылает их (по email, slack или другим методам) следуя вашим правилам (маршрутизация, эскалация).
Alertmanager
Ниже приведен пример настройки prometheus-operator Helm чарта. Вы можете изменять эти значения в values.yaml-файле Prometheus (секция alertmanager):
# alertmanager configuration
alertmanager:
# global route configuration
config:
global:
resolve_timeout: 5m
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 24h
receiver: 'default'
routes:
- match:
alertname: Watchdog
receiver: 'null'
receivers:
- name: 'null'
- name: 'default'
email_configs:
- send_resolved: true
from: "[email protected]"
to: "[email protected]"
smarthost: "mta:25"
require_tls: false
Тут вы можете видеть 2 получателя (null и default). Получатель default имеет email_configs с настройками почты.
Читайте подробнее о способах маршрутизации и доставки уведомлений тут:
- https://prometheus.io/docs/alerting/configuration/#email_config
- https://medium.com/curai-tech/constant-vigilance-a-step-by-step-guide-to-alerts-with-helm-and-prometheus-ae9554736031
Prometheus
-
Перейдите на страницу prometheus /alerts и найдите правило TargetDown. Исходный код этого правила вы можете найти в файле
prometheus-operator/templates/prometheus/rules/general.rules.yaml. Таким образом по его подобию вы можете задать свои новые правила срабатывания уведомлений. -
Если вы хотите взять готовые правила из yaml-file, то их следует сконвертировать в формат шаблона Helm. Для этого вы можете использовать данный скрипт:
prometheus-operator/hack/sync_prometheus_rules.py, добавив туда ссылку на файлы с вашими правилами:
{
'source': 'https://raw.githubusercontent.com/etcd-io/etcd/master/Documentation/op-guide/etcd3_alert.rules.yml',
'destination': '../templates/prometheus/rules',
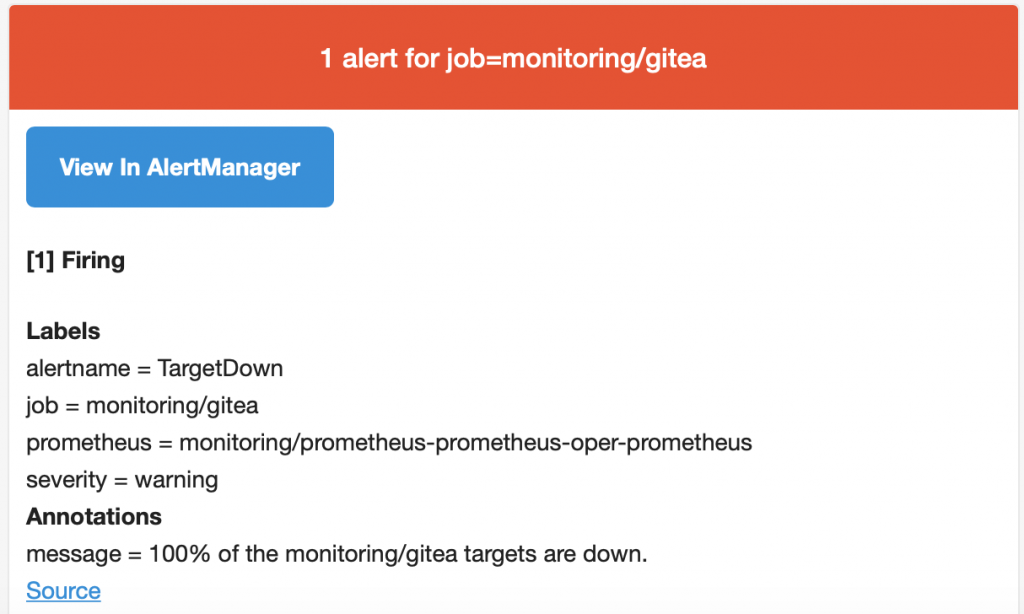
Это пример правила TargetDown:
alert: TargetDown
expr: 100
* (count by(job, namespace, service) (up == 0) / count by(job, namespace, service)
(up)) > 10
for: 10m
labels:
severity: warning
annotations:
message: '{{ $value }}% of the {{ $labels.job }} targets are down.'
Вы можете заметить, что оно базируется на выражении up == 0 . Проверьте его, сделав запрос в веб интерфейсе Prometheus:
Запрос вида: up == 0 – покажет вам сколько сервисов находится в состоянии down.
- Для проверки срабатывания правила – выключите один из pod-ов.
- Сначала правило перейдет в состояние
PENGING(потому как правило имеет 10 минутный таймаут). - После чего оно перейдет в состояние
FIRING. И вы сможете увидеть его на странице alertmanager /alerts. - Теперь можете смотреть логи вашего mta и проверять почтовый ящик.
- Сначала правило перейдет в состояние